K-means
Algoritmy - Učenie bez učiteľa
Algoritmus k-means je najpoužívanejší algoritmus nehierarchickej zhlukovej analýzy. Rieši problém zhlukovania, ktorý vytvára zhluky prvkov s podobnými vlastnosťami. Zhlukovanie sa podobá klasifikácii, ale na rozdiel od nej zaraďuje prvky do tried bez mien.
Priebeh
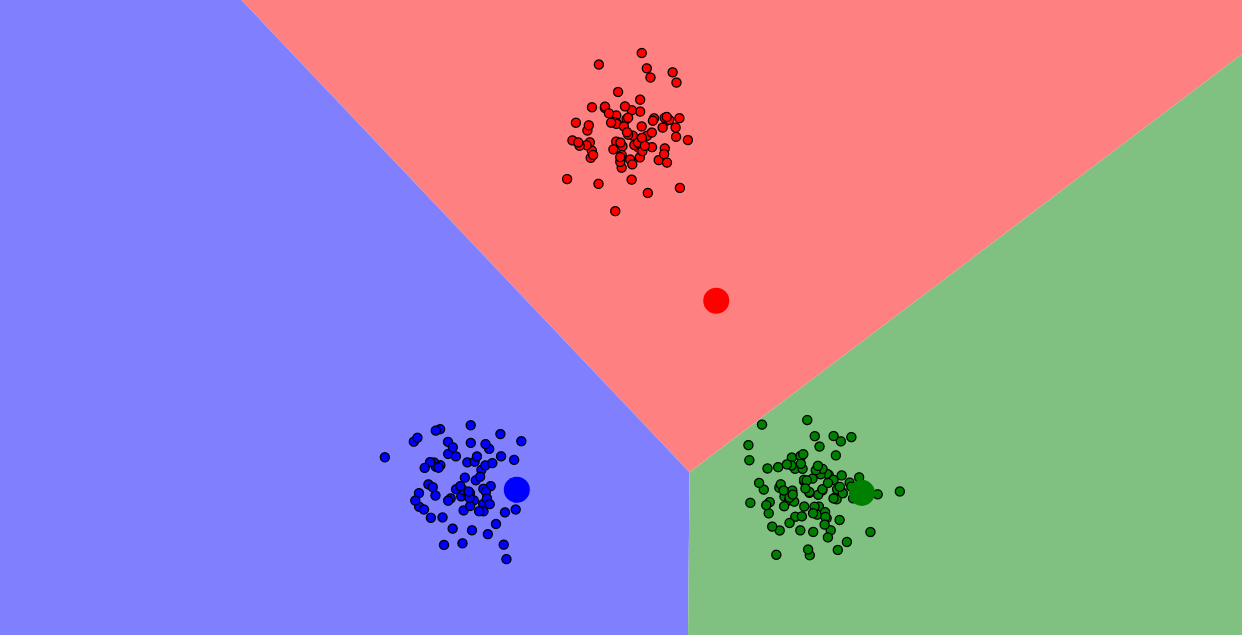
Algoritmus k-means (obr. 1) funguje v dvoch krokoch. Prvým je priraďovanie. Najprv sa do priestoru so zhlukmi pridá niekoľko centroidov, čo sú body definujúce jednotlivé zhluky a neskôr by sa mali nachádzať v strede zhluku. Centroidy sú pridané na náhodné pozície a mal by ich byť rovnaký počet, ako počet zhlukov. Centroidy sa pri krokoch algoritmu môžu pohybovať, ale dátové body musia zostať nehybné. Body sa zaradia do zhluku, ktorého centroid je bodu najbližšie
Ďalším krokom je optimalizácia. V tomto kroku sa centroidy posunú do stredu oblasti, v ktorej sú umiestnené body ich kategórie. Následne sa im znova priradia najbližšie body. Poloha centroidu sa znova prepočíta tak, aby tvoril ťažisko svojho zhluku. Tento proces sa opakuje, pokiaľ sa poloha centroidov neustáli. Po tomto procese sa centroidy z priestoru odstránia a vzniknú označené zhluky, ktorých body majú podobné vlastnosti.
Obrázok
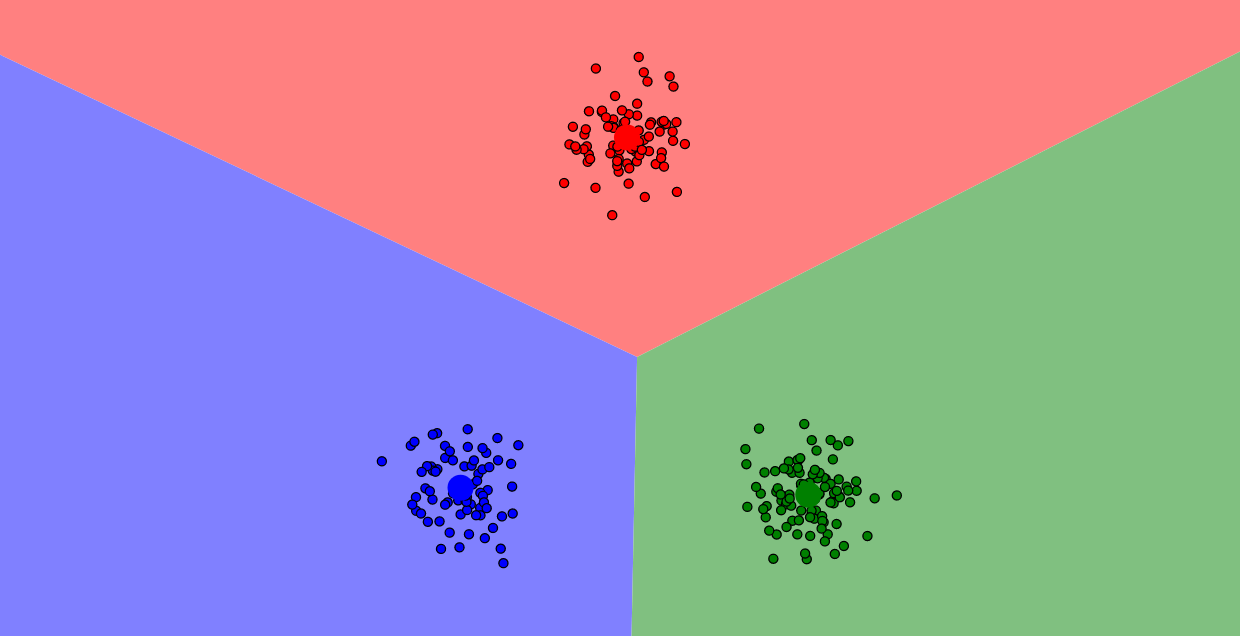
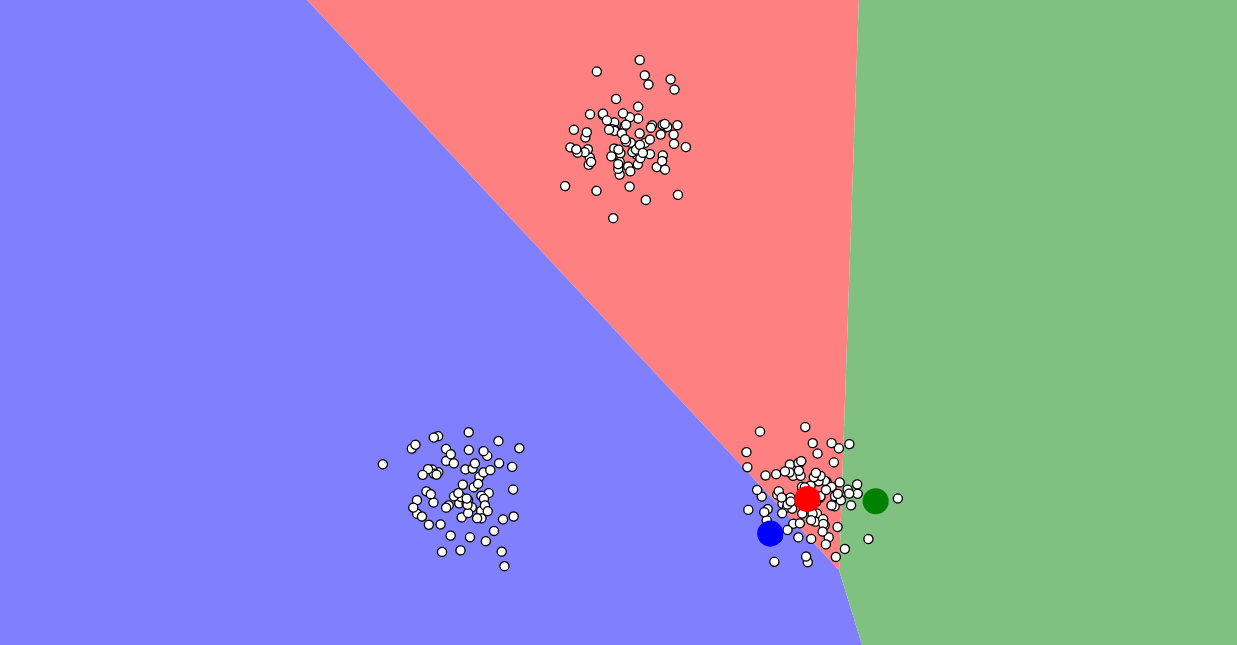
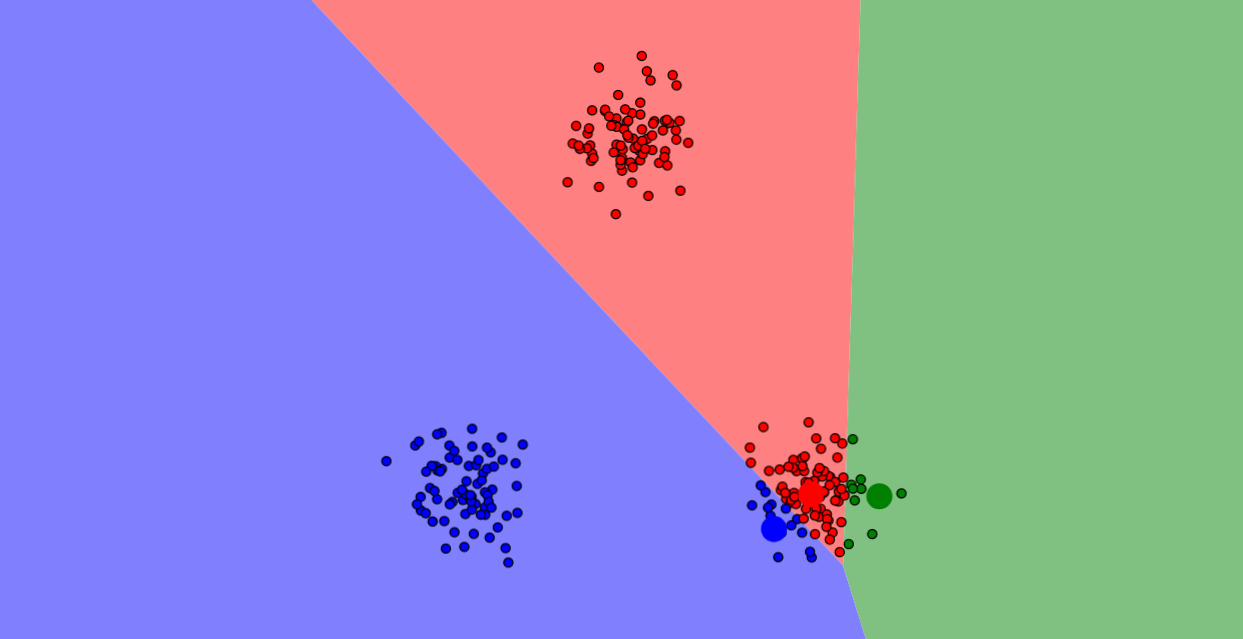
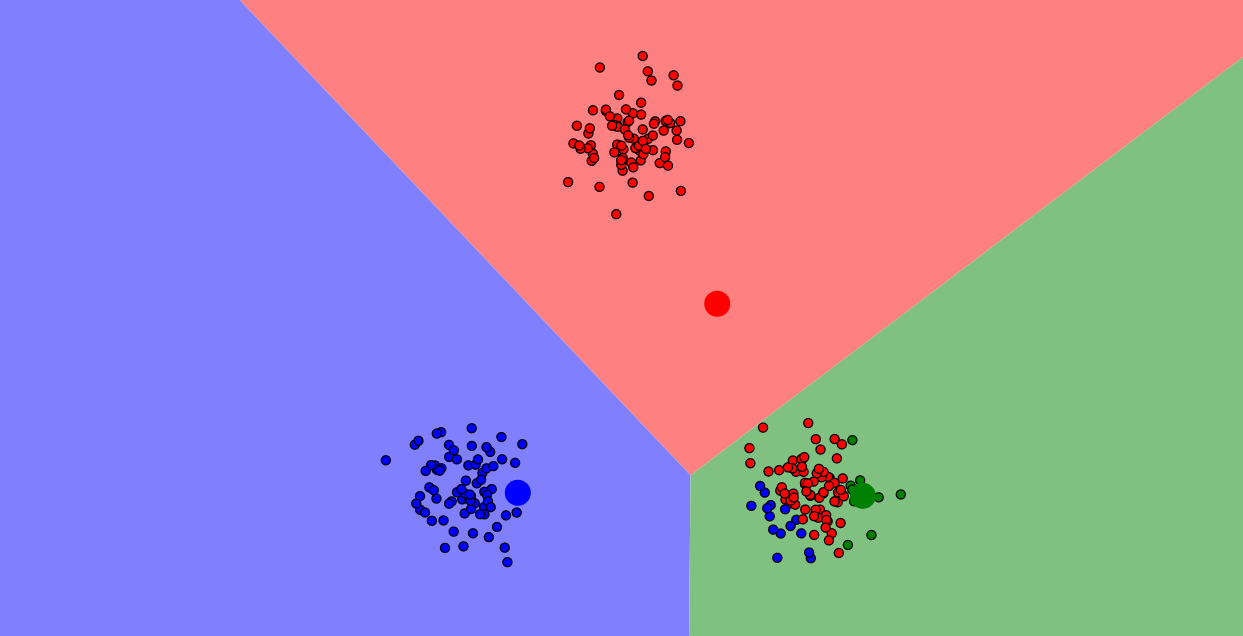
Vizualizácia postupu algoritmu k-means. Malé kruhy sú dátové body, veľké farebné kruhy sú centroidy. Farebné oblasti sú oblasti pôsobenia jednotlivých centroidov. Dátové body patria tomu centroidu, ktorého majú farbu. Vizualizácia vznikla pomocou vizualizačného nástroja Naftaliho Harrisa.
Krok 1

Krok 2
Krok 3
Krok 4
Krok 5
Krok 6