Učenie s učiteľom
Fungovanie vo všeobecnosti
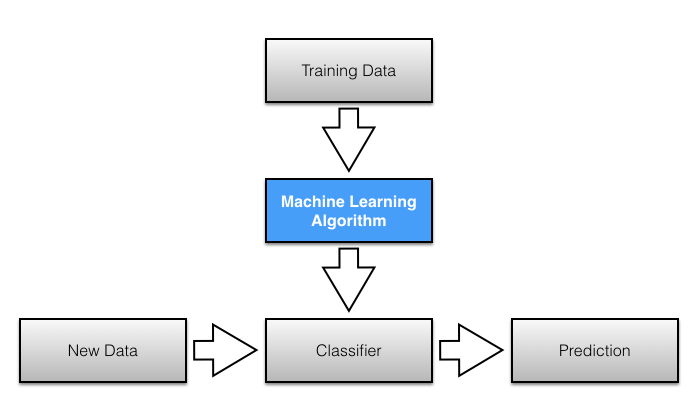
Učenie s učiteľom je metóda strojového učenia, v ktorej sa funkcia učí z tzv. datasetu.
Dataset
Dataset je súbor cvičných dát, z ktorých sa funkcia učí vzory a súvislosti v dátach. Dataset tvoria vždy dve skupiny prvkov – features a labels.
Features sú skúmané vlastnosti objektu. Tieto vlastnosti nemusia byť zahrnuté v datasete všetky, stačia iba tie, ktoré vedia objekty od seba spoľahlivo odlíšiť. Labels sú označenia vlastností objektu, resp. výsledné hodnoty po aplikácií funkcie. Tieto označenia sú v datasete známe, aby sa funkcia vedela naučiť odhadnúť výsledky. V reálnom použití sú však označenia neznáme a program ich musí vedieť vypočítať.
Príkladom môže byť identifikácia ovocia na základe jeho tvaru, farby a veľkosti. Features alebo vlastnosti by boli: guľatý tvar, oranžová farba a stredne veľký. Označenie, teda label by bolo pomaranč. Tvar by ho vedel odlíšiť napríklad od banánu, farba od jablka a veľkosť od mandarínky. Pri dostatočnom nacvičení na množstve takýchto údajov by funkcia dokázala identifikovať ovocie po zadaní týchto troch údajov.
Určovanie úspešnosti algoritmu
Určovanie úspešnosti algoritmu sa robí procesom nazývaným krížová validácia (angl. Cross-validation). Krížová validácia sa vykonáva len pri klasifikácii. Dataset sa rozdelí na dve podmnožiny – tréningovú a testovaciu. Tréningová, ktorá je väčšia ako testovacia, sa využíva na učenie programu a testovacia na meranie jeho úspešnosti. Po natrénovaní funkcie sa testovacia podmnožina vloží ako vstup do programu a jeho výstup sa porovná so správnym výstupom v testovacej podmnožine datasetu.
Problémy
Niekedy dochádza k javu zvanému overfitting. Pri ovefitting-u sa model učí príliš detailne a snaží sa správne klasifikovať aj šum alebo náhodné fluktuácie. Vtedy sa model sústreďuje na prvok dát osobitne, čo negatívne ovplyvňuje jeho schopnosť zovšeobecňovať svojej poznatky a schopnosť predikcie. Overfitting vzniká pri nedostatku tréningových dát alebo pri veľkom množstve ich parametrov a parametrov modelu.
Opakom overfitting-u je underfitting, pri ktorom modelu unikajú relevantné spojenia medzi dátami. Pri underfitting-u nemá algoritmus schopnosť učiť sa a ignoruje dát, takže jeho výstup nezávisí od naučených dát.
Ďalším problémom pri strojovom učení s učiteľom je tzv. bias-variance tradeoff. Tu ide o kompromis medzi chybami bias a variance, ktorý musí programátor nájsť, aby bol jeho algoritmus úspešný. Pri chybe bias dochádza k underfitting-u a pri chybe variance k overfitting-u.