Praktická ukážka
Tento program klasifikuje kosatce do troch druhov: Iris setosa, Iris versicolor a Iris virginica. Program klasifikuje kosatce podľa rozmerov kališných a okvetných lístkov. Na to využíva klasifikátor SVM a je naprogramovaný v jazyku Python s knižnicami scikit-learn a pandas.
Dataset
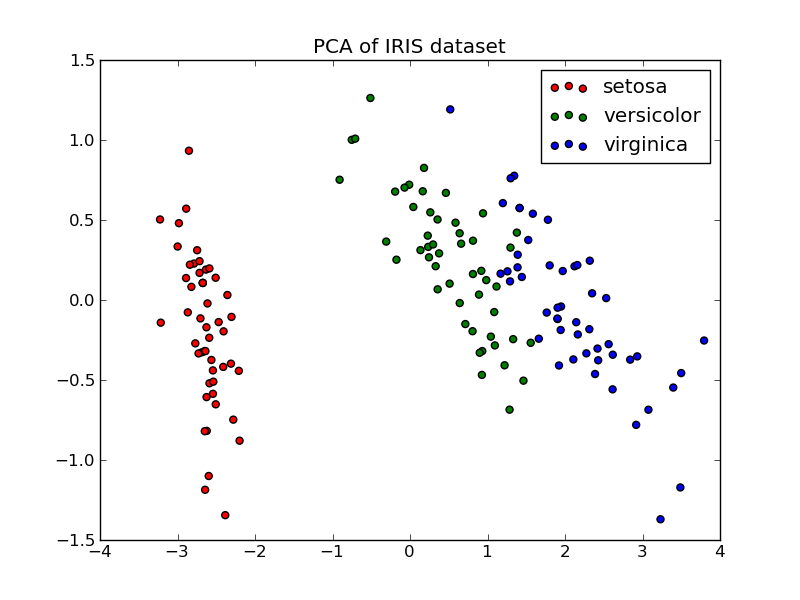
Dataset rastlín rodu Iris vytvoril v roku 1936 britský štatistik a biológ Ronald Fisher, ako príklad pre použitie lineárnej diskriminačnej analýzy. Tento dataset je veľmi populárny vzhľadom na to, že je jednoduchý, má malý počet prvkov a je ľahko lineárne rozdeliteľný (obr. 1).
Dataset obsahuje 150 prvkov pozostávajúcich z rozmerov v centimetroch okvetných a kališných lístkov. Každý prvok obsahuje štyri vlastnosti, a to dĺžku a šírku okvetných lístkov a dĺžku a šírku kališných lístkov. Ku každému prvku je priradené jedno označenie, o aký druh rastliny sa jedná – Iris setosa, Iris versicolor a Iris virginica (obr. 2).
Dataset je určený pre klasifikáciu, ale pri použití zhlukovania je nepoužiteľný, pretože dáta sú premiešané a bez daných označení ich nie je možné identifikovať v zhluku.
Tento program používa dataset z archívu University of California, Irvine (UCI), UC Irvine Machine Learning Repository, ktorý slúži ako databáza pre množstvo datasetov určených pre klasifikáciu, regresiu a zhlukovanie.
Knižnica scikit-learn
Knižnica scikit-learn alebo sklearn je open-source knižnica, ktorá ponúka všetky nástroje pre prácu so strojovým učením a hĺbkovou analýzou dát v programovacom jazyku Python. Knižnica sklearn je navrhnutá tak, aby sa s ňou dalo jednoducho spolupracovať s knižnicami NumPy, SciPy a matplotlib. Knižnica taktiež disponuje obsiahlou dokumentáciou s množstvom príkladov.
Program
Kódový zápis praktickej ukážky je nasledovný:
Importovanie knižníc
Prvý odsek importuje do programu potrebné knižnice. Knižnica pandas sa bude využívať na čítanie datasetu z webovej stránky. Ostatné riadky importujú rôzne súčasti knižnice sklearn, ktoré bude program využívať na spracovanie datasetu a strojové učenie.
Spracovanie datasetu
Druhý odsek číta dataset. Do pola header sa načítajú názvy jednotlivých stĺpcov v datasete, ktoré sa budú nachádzať v hlavičke. Následne sa do premennej data načíta pomocou príkazu read_csv dataset z uvedenej webovej stránky a do hlavičky sa mu vložia názvy stĺpcov predtým definované v poli header. Dataset sa dá načítať aj z lokálnej adresy v počítači.
Tretí odsek spracúva dataset. Najprv ho prekonvertuje a uloží do dvojrozmerného pola, resp. matice arr. Tú potom rozdelí na vlastnosti (features) a označenia (labels). Následne rozdelený dataset funkcia train_test_split rozdelí na testovaciu a tréningovú podmnožinu, ktoré sa umiestnia do štyroch polí. Parameter test_size určuje veľkosť testovacej podmnožiny, ktorá má v tomto prípade veľkosť 20 % datasetu.
Jadro programu
Štvrtý odsek vykonáva strojové učenie. Najprv do premennej clf umiestni klasifikátor algoritmu SVM zvaný Support Vector Classifier (SVC). Keďže vieme, že dataset je lineárne rozdelený, v parametri jadra použijeme lineárne jadro. Funkcia fit nacvičí jadro na tréningovej podmnožine datasetu. Do pola pred sa uložia predpovedané hodnoty, ktoré program získal aplikovaním klasifikátora na testovaciu podmnožinu dát.
Meranie úspešnosti algoritmu
Piaty odsek zisťuje úspešnosť algoritmu. Do premennej acc sa uloží výsledok funkcie accuracy_score, ktorá má za úlohu porovnať výsledky klasifikátora so správnymi výsledkami v datasete. Z toho určí percentuálnu úspešnosť algoritmu, ktorú vypíše funkcia print. Úspešnosť algoritmu SVM v tomto programe je 96,67 %.
Vstup používateľa
Posledný odsek funguje ako vstup pre používateľa programu. Tu sa reálne dáta v podobe rozmerov lístkov v centimetroch zadajú do hranatých zátvoriek funkcie predict, ktorá si vyžiada predikciu na zadané dáta od algoritmu. Tú uloží do premennej pred a tú vypíše funkcia print.
Konzola
V tejto interaktívnej konzole si môžete vyskúšať verziu programu praktickej ukážky. Program bol trochu zmenení pre jednoduchšiu manipuláciu a estecickosť, ale jadro je rovnaké.
Na vrchnej polovici, v karte main.py, môžete vidieť kód, ktorý táto konzola používa. Tento kód môžete upravovať a sledovať zmeny správania sa programu. V druhej karte, iris.csv sa nachádza dataset potrebný pre beh tohto programu.
Po načítaní stránky vás okno požiada o prihlásenie. Toto môžete ignorovať a zatvoriť. V tomto prípade sa však všetky zmeny, ktoré ste urobili v programe po každom načítaní vymažú. Pre zachovanie vašich zmien je potrebné sa zaregistrovať a prihlásiť.
Pre spustenie programu stačí stlačiť tlačidlo run alebo Ctrl + Enter.